- TradeWithTitans Newsletter
- Posts
- My New ETH Strategy to DeepSeek Higher Prices
Traders,
I’m going to start by calling it like it is: ETH has been a damn roller coaster lately. If you happened to get your face ripped off, believe me — you’re not alone. I took some lumps too. That’s just the trading game sometimes: you either cry in a corner or you adapt, and I prefer to do the latter.
Here’s how I adapted:
Updated My Plan
Developed a New ETH Strategy
Pestered my quants to see if DeepSeek signals Armageddon for NQ
If you’re short on time, you can skip around. But if you actually want to step your game up, read all the juicy bits. And heads up: memberships close in 1 week! I’m not sure when I’ll open them again. Could be a month, could be never, or it could be tomorrow if I have a change of heart — but I doubt that. You’ve been warned.
By the way, a bunch of you have reached out to me saying you want to join but the price makes out of reach. While I’m not apologetic about refunding & sending back folks who are in deep debt or looking to risk it all on one big trade, if you need a helping hand, reply to this e-mail, and I’ll see what the team can do.
My New Plan
Last time we talked, I had my eye on levels around 6076. Then out of nowhere, some 5 day old news about a Chinese hedge fund started ripping through the market. Fun times.
Let’s be real: I’m not going to beat myself up too much. Anyone who joined our live sessions knows 6076 gave us plenty of scalps. The beauty of order flow is that it’s the one signal actually happening in real time. No guesswork, no “psychic hotline” BS. If I see that liquidity is drying up at 6076 — or better yet, actual sellers are taking it by the throat — I’m not going to fade that. DOM is everything. You either watch it like a hawk, or you watch your PnL vanish.
But let’s highlight some real trades for you:
Sunday night’s ETH session: Most of the room shorted it using my brand-spankin’-new ETH strategy (we’ll get to that). For those of you who didn’t stay up, we had an absolute banger Monday morning live.
Our quant wizard “Usual Whale” spent the weekend dissecting DeepSeek and concluded the entire fiasco was “overblown.” So, when RTH opened and volatility died, he went long 21230 and locked in profits around 21400-420.
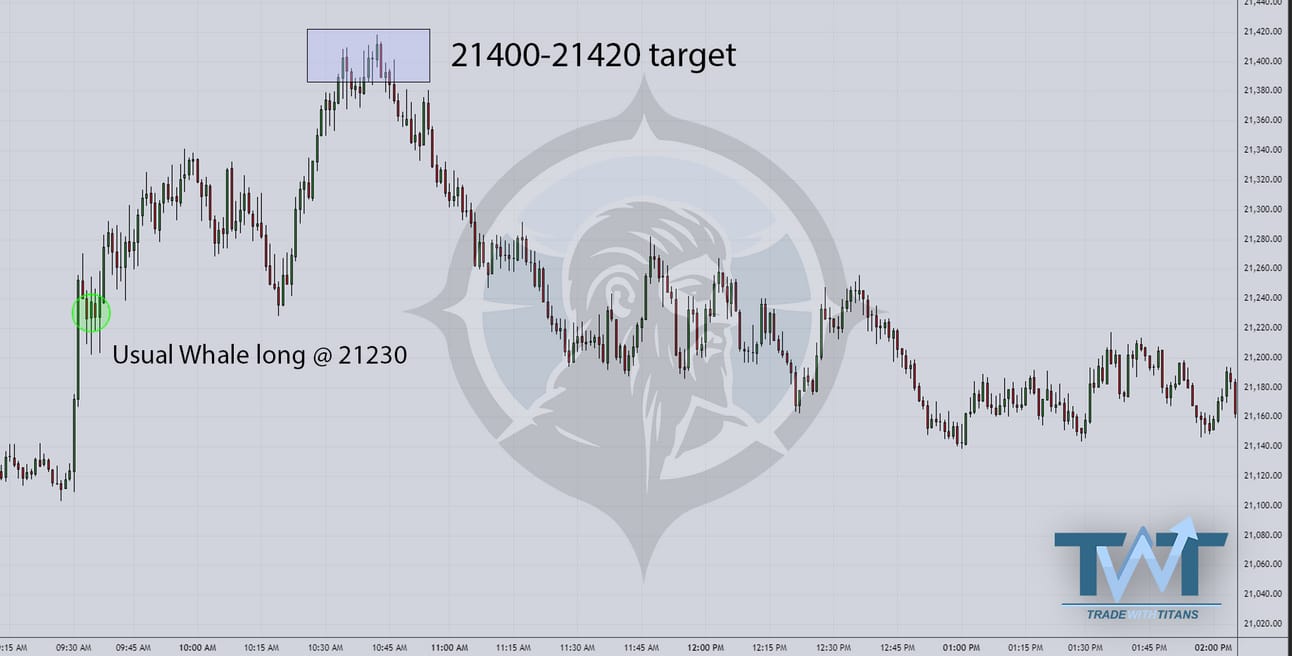
Usual Whale called the market’s AM bluff to perfection.
Our members enjoyed as well:
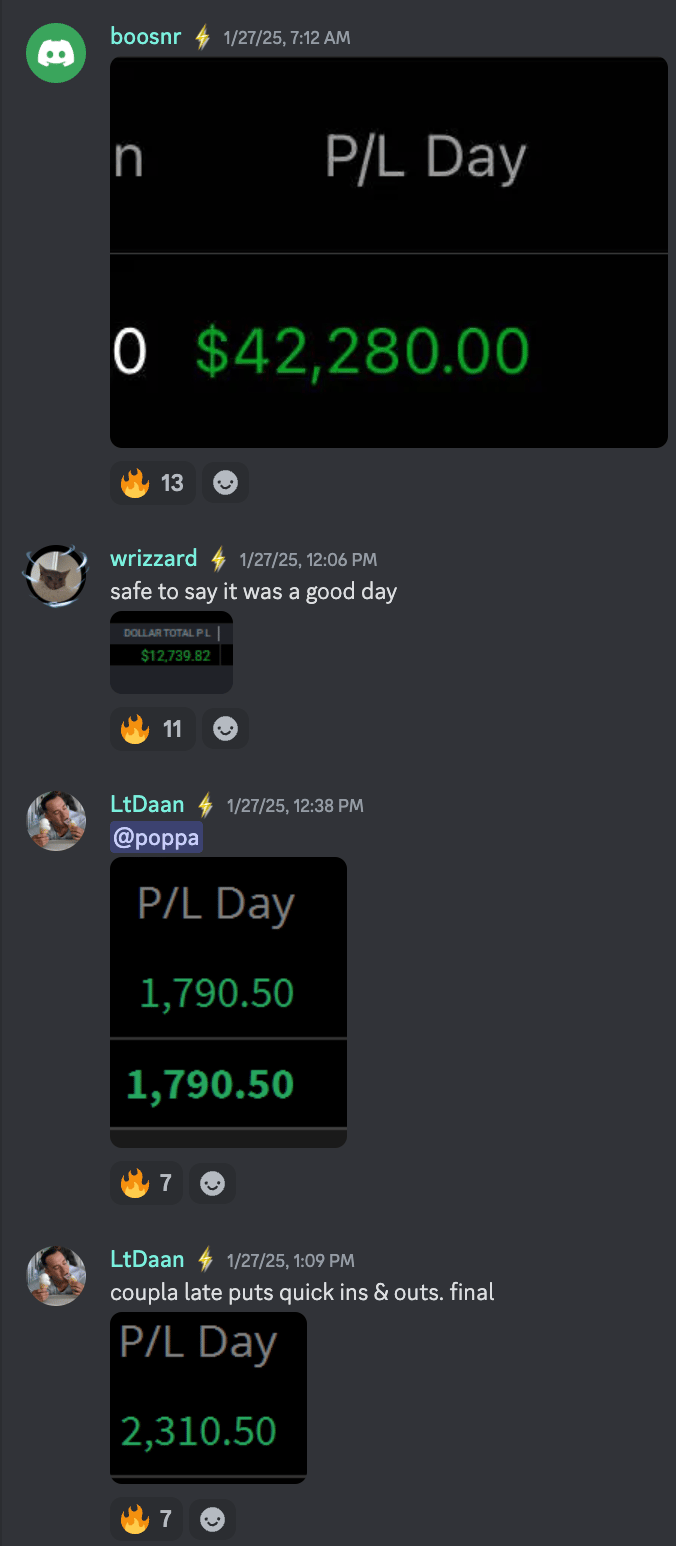
Our members were on the right side of the move.
Bottom line: updating your bias based on real-time cues is what keeps you alive in this game. If you want to keep ignoring that, be my guest, but let me know how that works out for you.
On Tuesday, I kept riding the bullish wave, longing 32s and eyeing 87s for my exit. (Ignore my butchered chart annotations—I was juggling a coffee in one hand and the DOM in the other.)
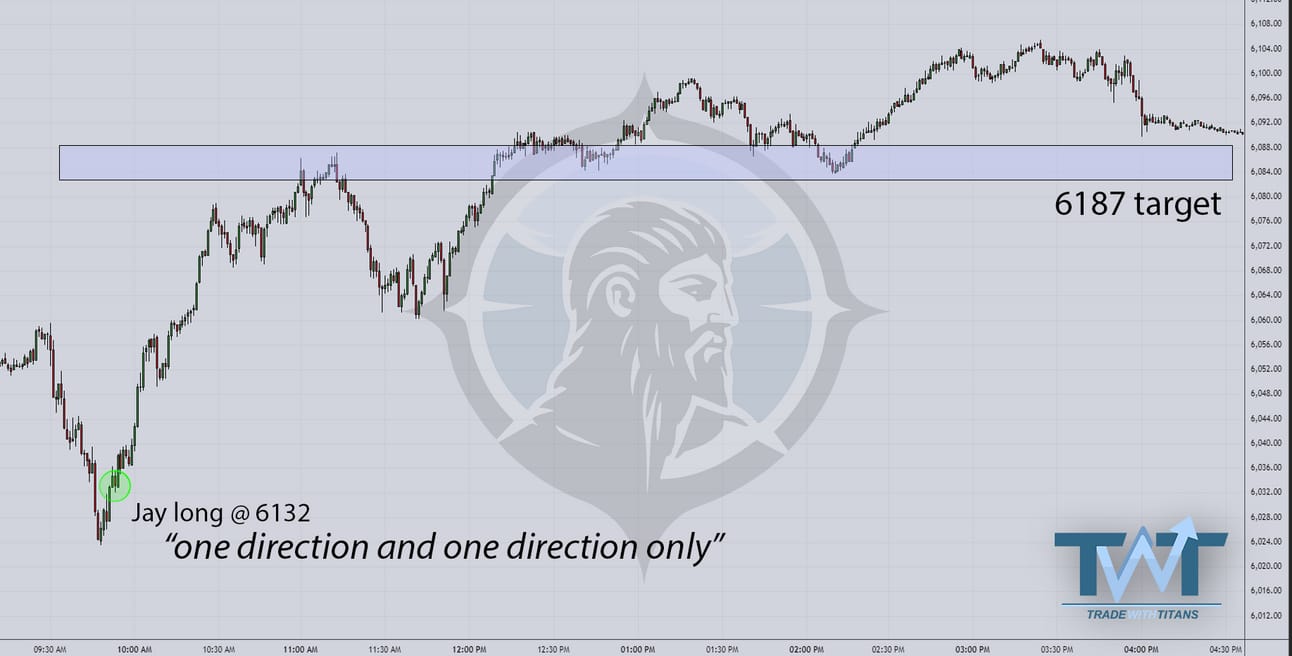
Just subtract 100 from these numbers :)
This is how I love to play these reversals. Don’t fall for the bear traps, but also respect the fact that sellers were serious (and may look to defend their positions) to avoid getting too greedy.
FOMC and some big earnings headlines had us reduce risk the rest of the week, but I’m still stalking my next move. The market’s shaping up into a nice triple distribution. (If the term “distribution” makes your eyes glaze over, that’s your problem. But I’ll throw you a bone in a second).
Triple Distribution vs. Double Distribution
You’ve probably heard me preach about the TWT double distribution approach: we look for the market to build (or “accept”) value in each distribution, then keep breaking out if volume and order flow support it. Right now, we’re basically seeing triple distributions. That means more levels and, frankly, more potential for bigger (and wilder) moves.
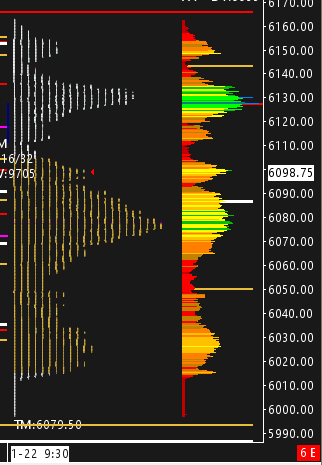
The Triple Distribution from this balance zone.
If that sounds like Klingon to you, here’s the simplified cheat sheet:
Upside: I’m watching 6132-42 as a zone where sellers might reappear to defend. If bulls smash through that, I’ll look toward 6190 (all-time highs) like a moth to a flame.
Downside: Keep your eyes on 6106 for clues — that’s my pivot. If we lose that, my next lines in the sand are 6059, 6044, and 6012.
By the way — if you want my chartbook so that you can also see the distributions forming clearly — it’s available for free in the Discord.
My New ETH Strategy
Over the years, I’ve realized the ETH (overnight) session can be a gold mine in the right market regime. In fact, I used to set my alarm at 3 AM EST for London’s open, place a few orders if the tape looked good, then zombie-walk back to bed. Now that I’m older —and let’s be honest, lazier about random 3 AM wake-ups — I said, “Screw it, let’s automate.”
So I told my quant team: “Build something that hunts like I do at 3 AM, minus the brain fog.” They took my notes on the typical overnight ranges, the pace of the tape, and possible fade setups. Then, they coded up the ETH Bot.
It’s in beta, but so far, it’s nearly unstoppable. The damn thing shorted Sunday night’s drop like it had tomorrow’s newspaper in hand. It might actually be better than our RTH Order Flow Bot (don’t let the RTH Bot hear me say that).
We just rolled this out for members. Check the alerts for this past week if you want full lowdown. If you’re still skeptical — maybe you trust your Great Aunt’s palm readings more than quants — that’s on you. But the proof is in the PnL.
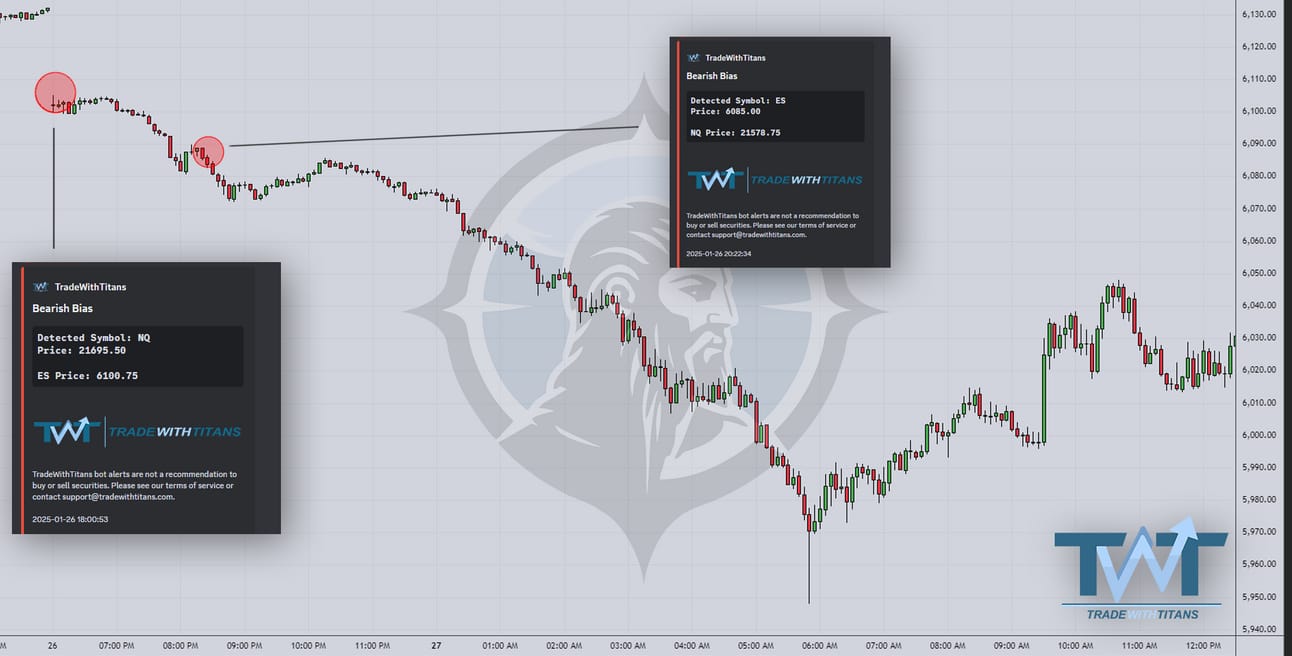
The bot caught Sunday night’s -3+% move! These were the only 2 alerts.
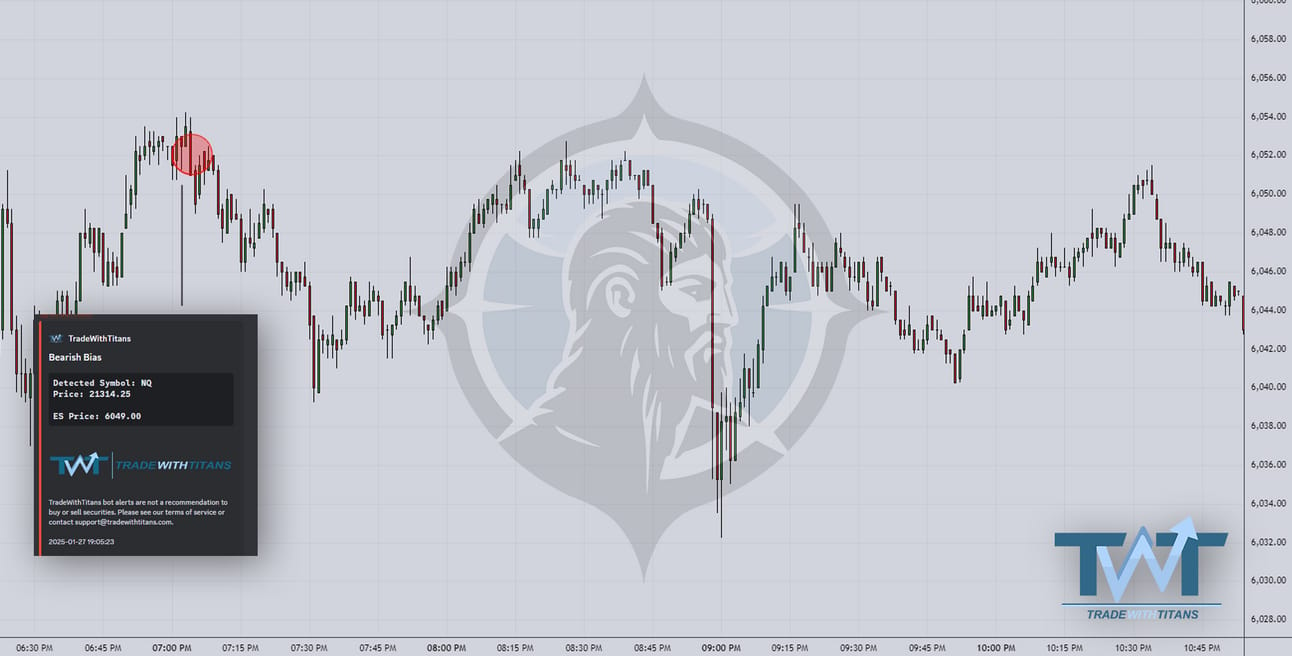
It called the pullback after Monday’s session as well!
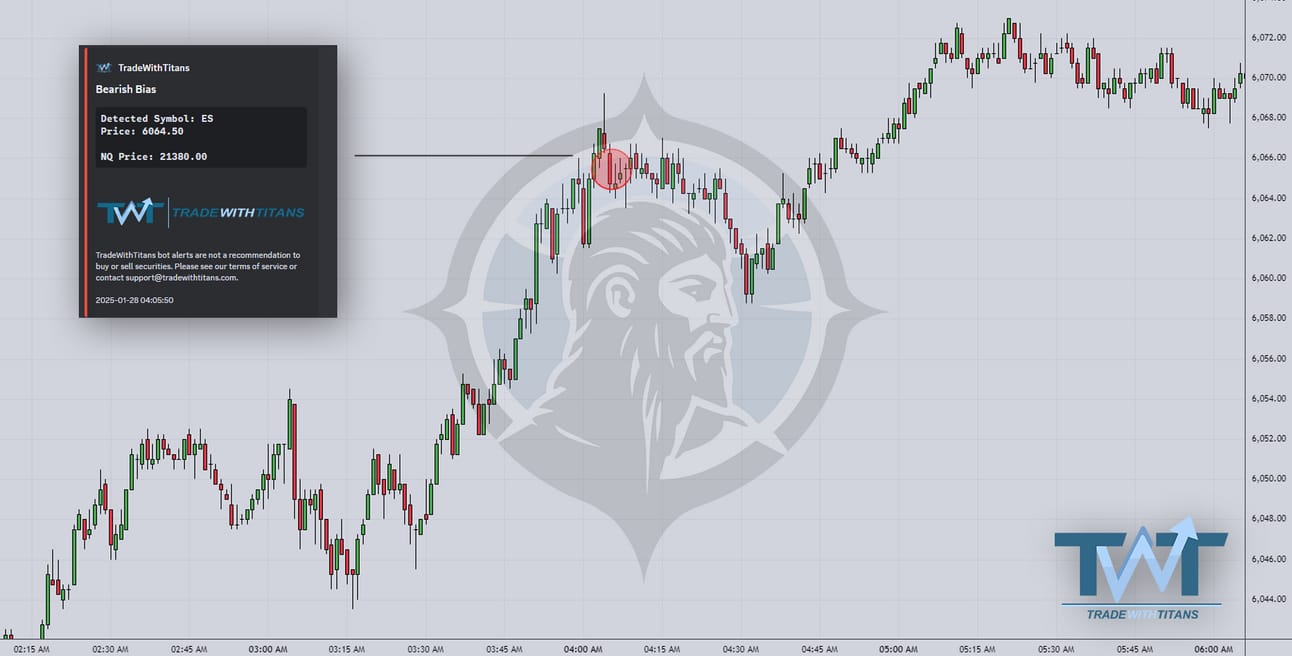
Tuesday AM saw a more scalpy alert, but still plenty of MFE!
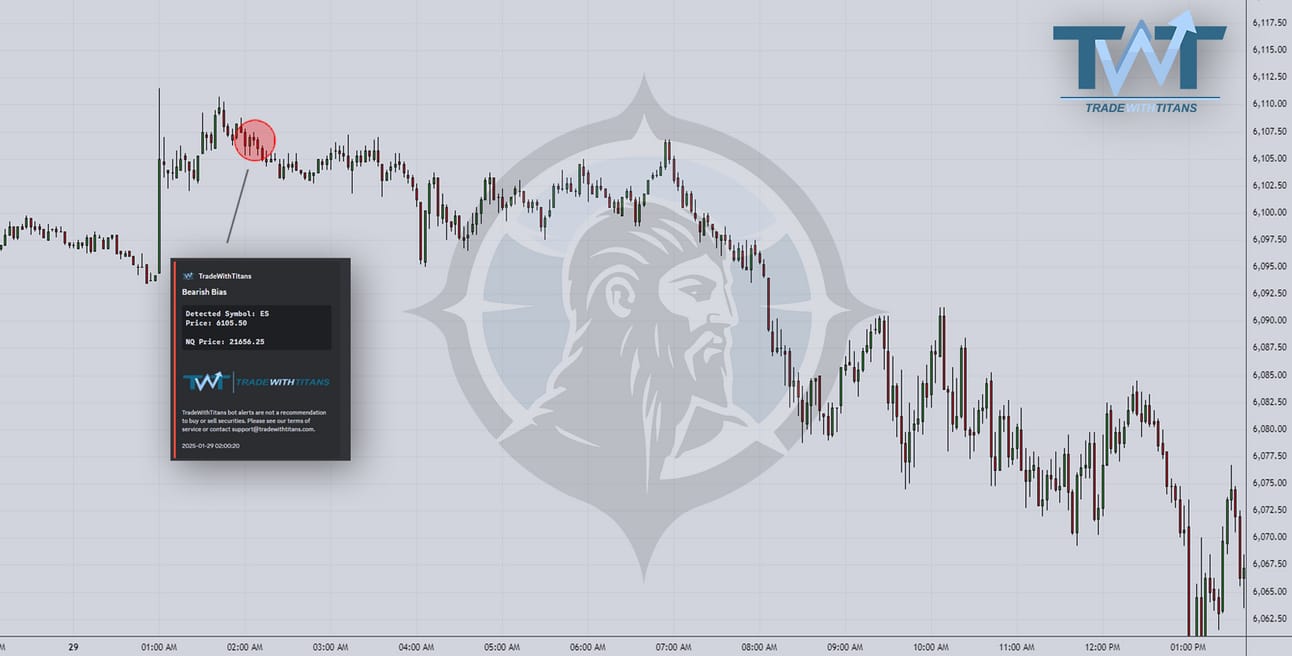
Wednesday AM saw another terrific short!
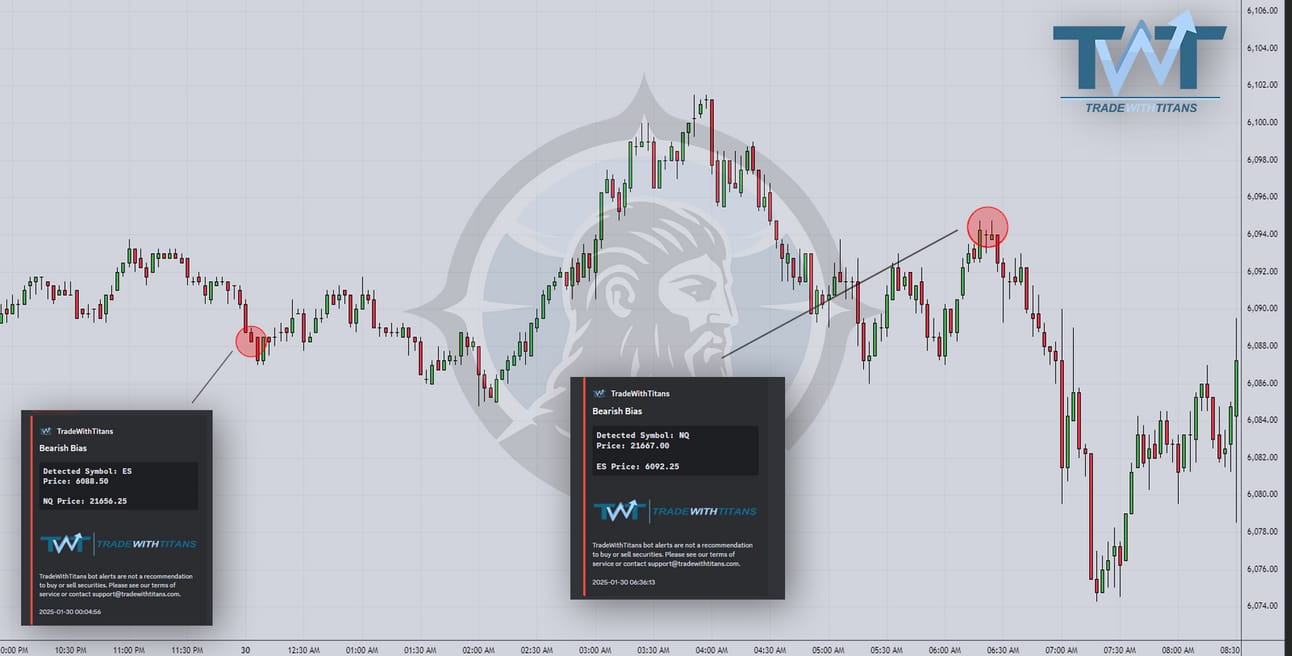
Thursday morning had one miss but a great final short into RTH.
Quant Team's Take on DeepSeek
Hey everyone, Usual Whale here from the TWT quant team. Jay asked me to share my perspective on DeepSeek and its implications for AI's future, both from technical and market perspectives.
While I wouldn't call myself the ultimate authority, I bring over a decade of deep learning experience to the table. Unlike many Twitter pundits, I've actually done my homework - reading through DeepSeek's papers and research thoroughly. So let me break this down without getting lost in technical minutiae.
The Technical Landscape
DeepSeek dropped a bombshell on the AI community by claiming they'd achieved state-of-the-art (SOTA) performance at a fraction of the typical cost - and supposedly as a side project, no less.
Their claims haven't gone unchallenged, particularly regarding transparency around total training costs. A crucial detail: their latest models aren't built from scratch but are iterations on previous models whose costs remain undisclosed. There's also widespread speculation about DeepSeek's hardware access. Many believe they possess more $NVDA GPUs than officially stated but keep quiet due to export control concerns. The fact that 22% of $NVDA’s sales go to Singapore - a tiny market - suggests a potential unofficial pipeline for Chinese buyers to acquire these coveted chips.
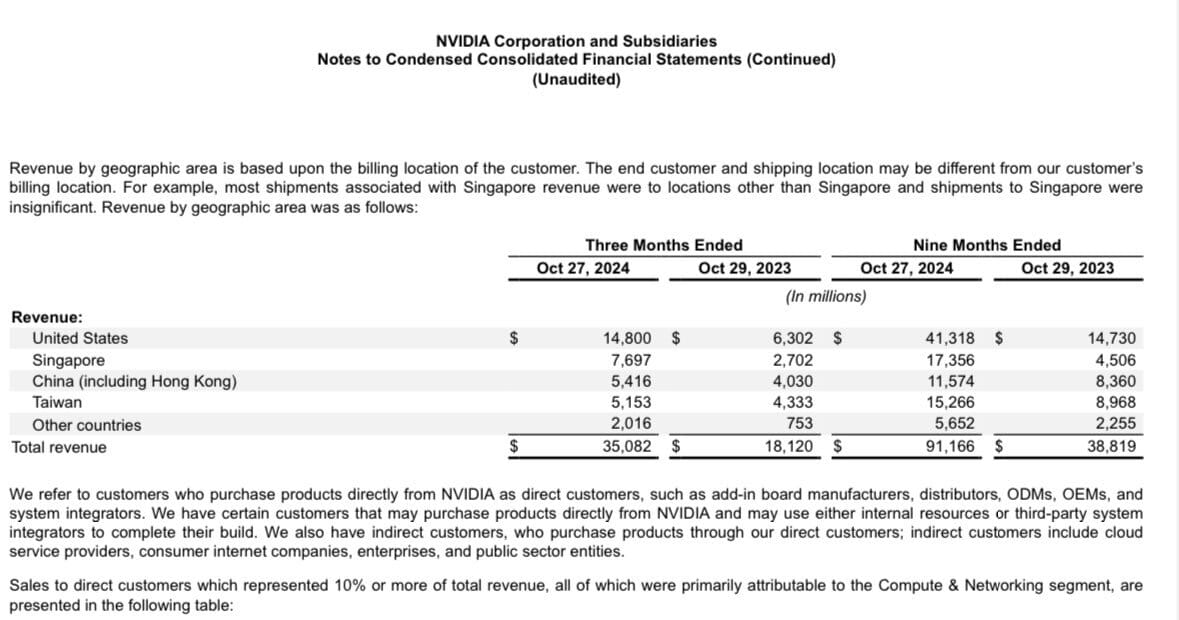
$NVDA sells a lot to such a small nation!
Despite these questions, DeepSeek's technical achievements are undeniably impressive. Their background in high-frequency trading equipped them with rare programming expertise that sets them apart in the AI field. One particularly fascinating aspect is their "hands-off" training approach, letting the model develop its own chain-of-thought reasoning for complex problem-solving. Their paper showcases some compelling examples of this methodology.

However, there's a significant caveat: DeepSeek benefited from a unique second-mover advantage. In today's AI landscape, companies typically prioritize model capability over cost efficiency. DeepSeek flipped this script. With benchmarks already established by pioneers like OpenAI, they could focus on optimization rather than breaking new ground.
This leads to some intriguing hypotheses:
DeepSeek might have actually trained against existing SOTA models from US tech giants. With original LLM training data increasingly restricted, they may have had little choice but to distill intelligence from these existing models into a more efficient form factor.
While DeepSeek has demonstrated remarkable optimization prowess in training and inference, the scalability of their methods remains questionable. Despite being open-sourced, crucial details about their build process are conspicuously absent from their paper. Some of these techniques were already known to US tech companies, but were previously dismissed for producing subpar results. Early reports suggest that while DeepSeek excels in benchmarks, its real-world performance might not match up to other SOTA models.
Market Implications
Now for what's probably on everyone's mind: the market impact.
The prevailing narrative suggests that DeepSeek's efficiency breakthrough makes US tech giants look foolish for pouring hundreds of billions into massive data centers. The thinking goes that if superior results don't require astronomical hardware investments, companies like $NVDA might see reduced demand. Given these companies' substantial weight in major indices, investors are understandably nervous.
Here's my nuanced take.
First, let's move beyond generalizations. In the US tech landscape, we need to distinguish between AI consumers and producers.
Take $AAPL - primarily an AI consumer. They're not focused on developing SOTA models but rather on integrating AI into smartphones efficiently. For them, lower-cost models requiring minimal hardware are ideal.
$META occupies a middle ground. While they develop their own models, they've positioned themselves as open-source leaders. DeepSeek's advances could actually benefit them - they have the resources to incorporate these innovations into their toolkit and potentially establish them as industry standards (think Android vs. iPhone).
Then there are the pure producers: OpenAI, Anthropic, and $GOOGL, who are pushing the boundaries of closed-source AI. For them, extensive hardware access isn't a liability - it's a competitive advantage. Advancing AI requires running numerous parallel experiments. If DeepSeek's efficiency innovations prove scalable, these companies can leverage their existing hardware to do exponentially more. And since model performance currently scales with inference compute, this likely means even better results.
As for everyone's favorite: $NVDA. Yes, decreased GPU demand would impact their bottom line. However, US tech giants haven't shown any signs of slowing their expansion plans, even after DeepSeek's announcement. Given AI models' growing compute hunger and the time required to build GPU-centric data centers, hardware still provides a genuine technical edge. If anything, more efficient hardware utilization only amplifies this advantage.
The real concern lies in investor perception of CapEx ROI. Markets have given these companies considerable latitude to expand expenses, betting on eventual AGI achievement or market dominance expansion. Two years in, revenue gains remain elusive. At some point, this shifts from potential breakthrough to expensive science experiment, and markets will react accordingly.
Current US tech valuations imply a significant expected return on CapEx investment. If confidence in achieving these returns wavers, stock prices will follow suit.
This explains why many tech CEOs are pushing the narrative about AI replacing junior engineers. From my conversations with technology executives, this appears to be misdirection. The real driver behind reduced hiring is pandemic-era overstaffing combined with unexpectedly low attrition rates (departments typically plan for certain annual turnover percentages, which have been significantly lower in recent years). Remember, without immediate revenue growth, cost reduction becomes the only path to increased profits. Outside of AI-related CapEx, engineering talent represents these companies' largest expense. This narrative buys time until they achieve a genuine product breakthrough.
As the saying goes, all bubbles eventually burst - timing is the only unknown. Whether we're actually in a bubble remains unclear. But in today's market, no one has the patience to risk holding the bag.
Want More of My Analysis?
Let me guess. You’re tired of losing sleep second-guessing trades. You’re fed up with half-baked setups from “trading gurus” who flex their Lambos but can’t explain delta. You want to actually catch highs and lows with near-surgical precision—without sacrificing your sanity.
Daily live trading on voice: Watch me rip the tape in real time and call out plays you’ll wish you’d thought of first.
Adam Set’s Journal: An unfiltered, borderline NSFW look into the mind of a real trader. If it’s in his head, it’s in that journal—no fluff, no BS, no sugarcoating.
Vol Bot, Order Flow Bot, and the new ETH Bot: Because manually flipping a coin at 2 AM isn’t a strategy, folks. Let the machines do the heavy lifting.
Daily Plans: If you think you can just “wing it” every morning and outsmart everyone, good luck. These plans give you a road map, so you know where the sneaky reversals might happen.
Educational Resources: From advanced DOM reading to strategic capital management. No stale kindergarten-level “here’s what a candlestick is,” but legit deeper-level knowledge you need to survive.
Memberships close next week. If you want in, do it now — or wait for the next time I get in a charitable mood. No promises.
Our promo codes are expired, but if you really need the help, e-mail me and we’ll see what we can do.
Not convinced? There’s a 7-day money back guarantee, so give it a shot, no risk!
Can’t Join Yet?
If you’re the impatient type, you can at least hop into our free Discord. You’ll find Adam’s Chartbook, a risk management guide to keep you from blowing your account, plus some of my live insights 2-3 times a week!
By the way, if you ever have questions or want me to roast your trade ideas (in a loving way, of course), reply to this email. I actually like engaging with people who show some hustle.
Jay